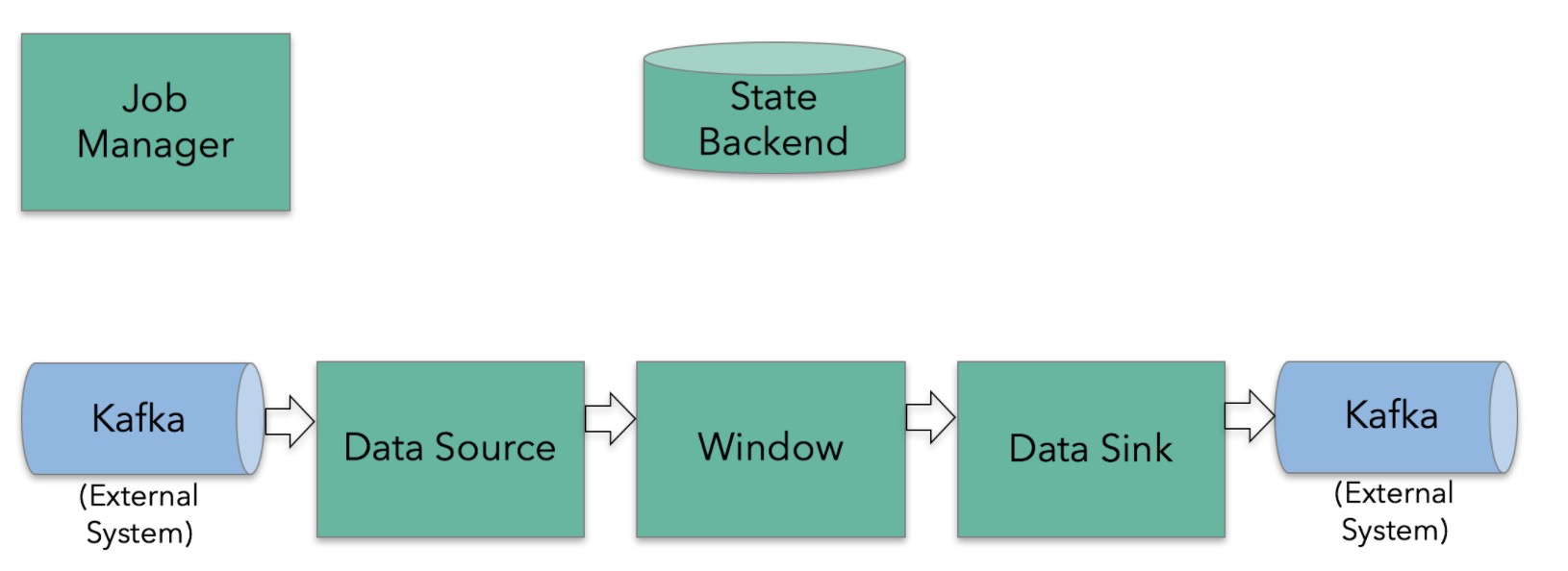
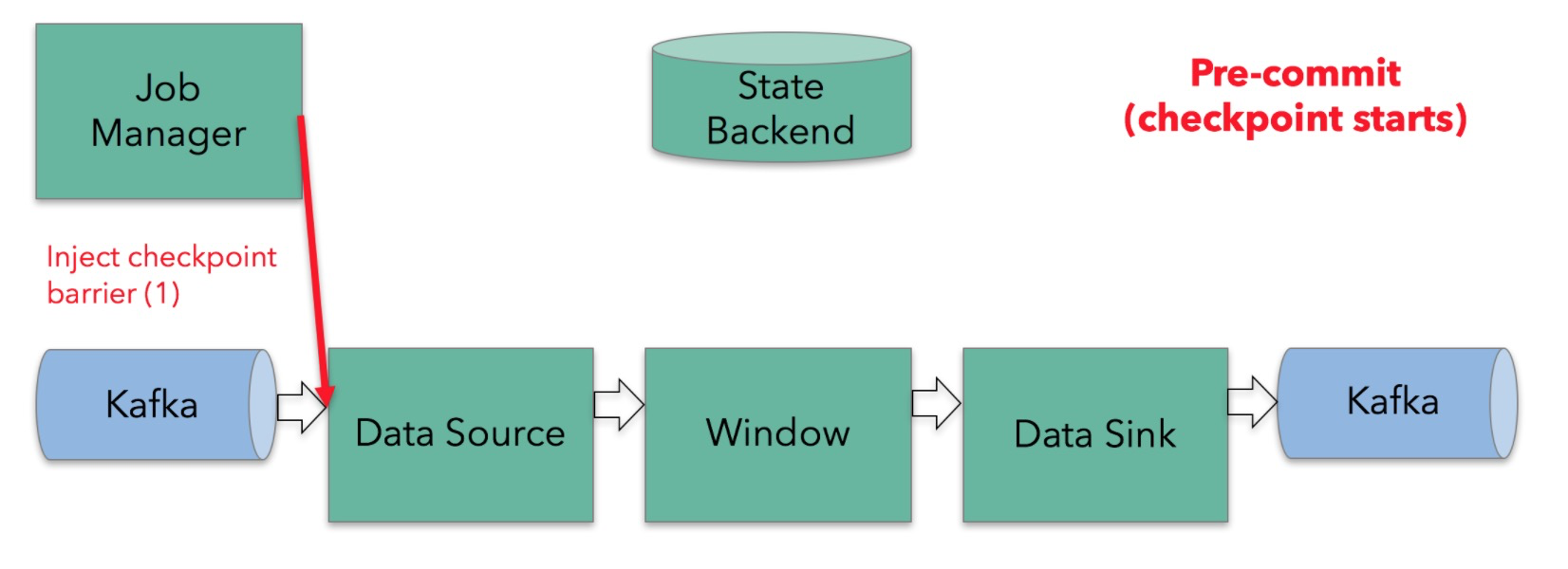
public abstract class TwoPhaseCommitSinkFunction<IN, TXN, CONTEXT>
extends RichSinkFunction<IN>
implements CheckpointedFunction, CheckpointListener {
protected final LinkedHashMap<Long, TransactionHolder<TXN>> pendingCommitTransactions = new LinkedHashMap<>();
protected transient Optional<CONTEXT> userContext;
protected transient ListState<State<TXN, CONTEXT>> state;
private final Clock clock;
private TransactionHolder<TXN> currentTransactionHolder;
private long transactionTimeout = Long.MAX_VALUE;
private boolean ignoreFailuresAfterTransactionTimeout;
private double transactionTimeoutWarningRatio = -1;
protected abstract void invoke(TXN transaction, IN value, Context context) throws Exception;
/**
* Method that starts a new transaction.
*
* @return newly created transaction.
*/
protected abstract TXN beginTransaction() throws Exception;
/**
* Pre commit previously created transaction. Pre commit must make all of the necessary steps to prepare the
* transaction for a commit that might happen in the future. After this point the transaction might still be
* aborted, but underlying implementation must ensure that commit calls on already pre committed transactions
* will always succeed.
*
* <p>Usually implementation involves flushing the data.
*/
protected abstract void preCommit(TXN transaction) throws Exception;
/**
* Commit a pre-committed transaction. If this method fail, Flink application will be
* restarted and {@link TwoPhaseCommitSinkFunction#recoverAndCommit(Object)} will be called again for the
* same transaction.
*/
protected abstract void commit(TXN transaction);
/**
* Invoked on recovered transactions after a failure. User implementation must ensure that this call will eventually
* succeed. If it fails, Flink application will be restarted and it will be invoked again. If it does not succeed
* eventually, a data loss will occur. Transactions will be recovered in an order in which they were created.
*/
protected void recoverAndCommit(TXN transaction) {
commit(transaction);
}
/**
* Abort a transaction.
*/
protected abstract void abort(TXN transaction);
/**
* Abort a transaction that was rejected by a coordinator after a failure.
*/
protected void recoverAndAbort(TXN transaction) {
abort(transaction);
}
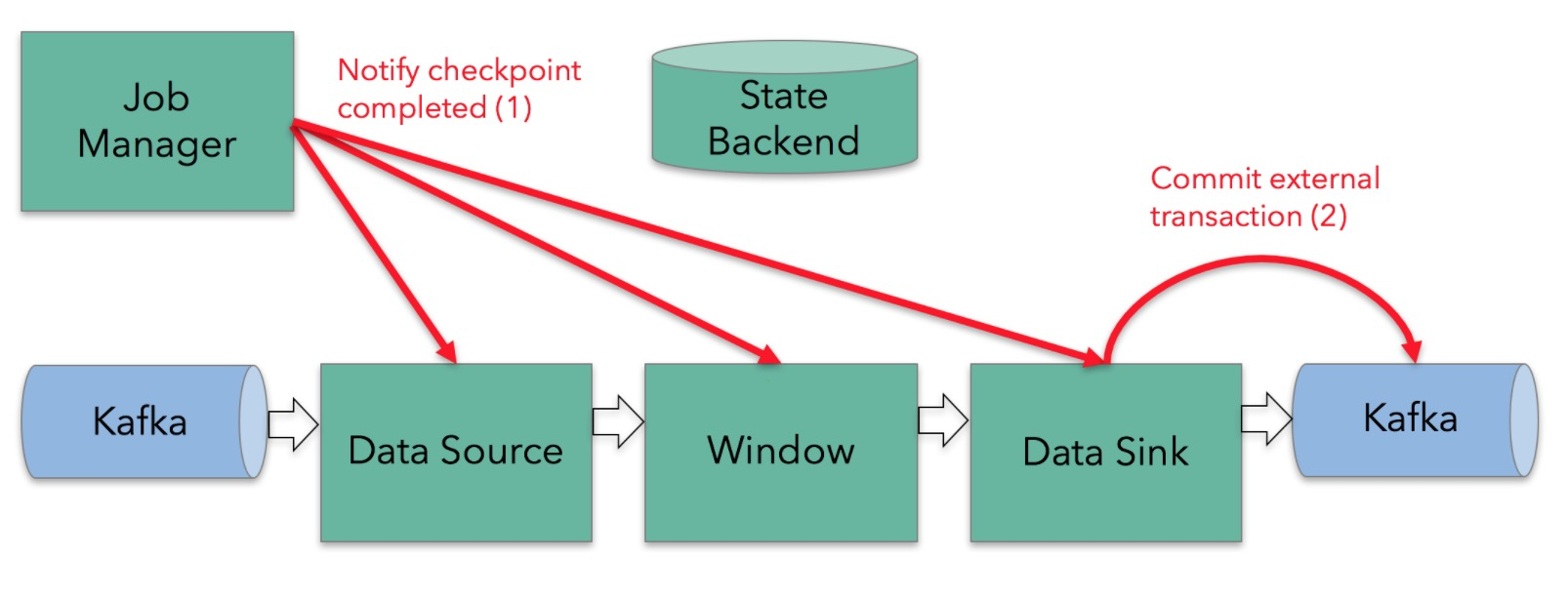
@Override
public final void notifyCheckpointComplete(long checkpointId) throws Exception {
Iterator<Map.Entry<Long, TransactionHolder<TXN>>> pendingTransactionIterator = pendingCommitTransactions.entrySet().iterator();
checkState(pendingTransactionIterator.hasNext(), "checkpoint completed, but no transaction pending");
Throwable firstError = null;
while (pendingTransactionIterator.hasNext()) {
Map.Entry<Long, TransactionHolder<TXN>> entry = pendingTransactionIterator.next();
Long pendingTransactionCheckpointId = entry.getKey();
TransactionHolder<TXN> pendingTransaction = entry.getValue();
if (pendingTransactionCheckpointId > checkpointId) {
continue;
}
LOG.info("{} - checkpoint {} complete, committing transaction {} from checkpoint {}",
name(), checkpointId, pendingTransaction, pendingTransactionCheckpointId);
logWarningIfTimeoutAlmostReached(pendingTransaction);
try {
commit(pendingTransaction.handle);
} catch (Throwable t) {
if (firstError == null) {
firstError = t;
}
}
pendingTransactionIterator.remove();
}
if (firstError != null) {
throw new FlinkRuntimeException("Committing one of transactions failed, logging first encountered failure",
firstError);
}
}
@Override
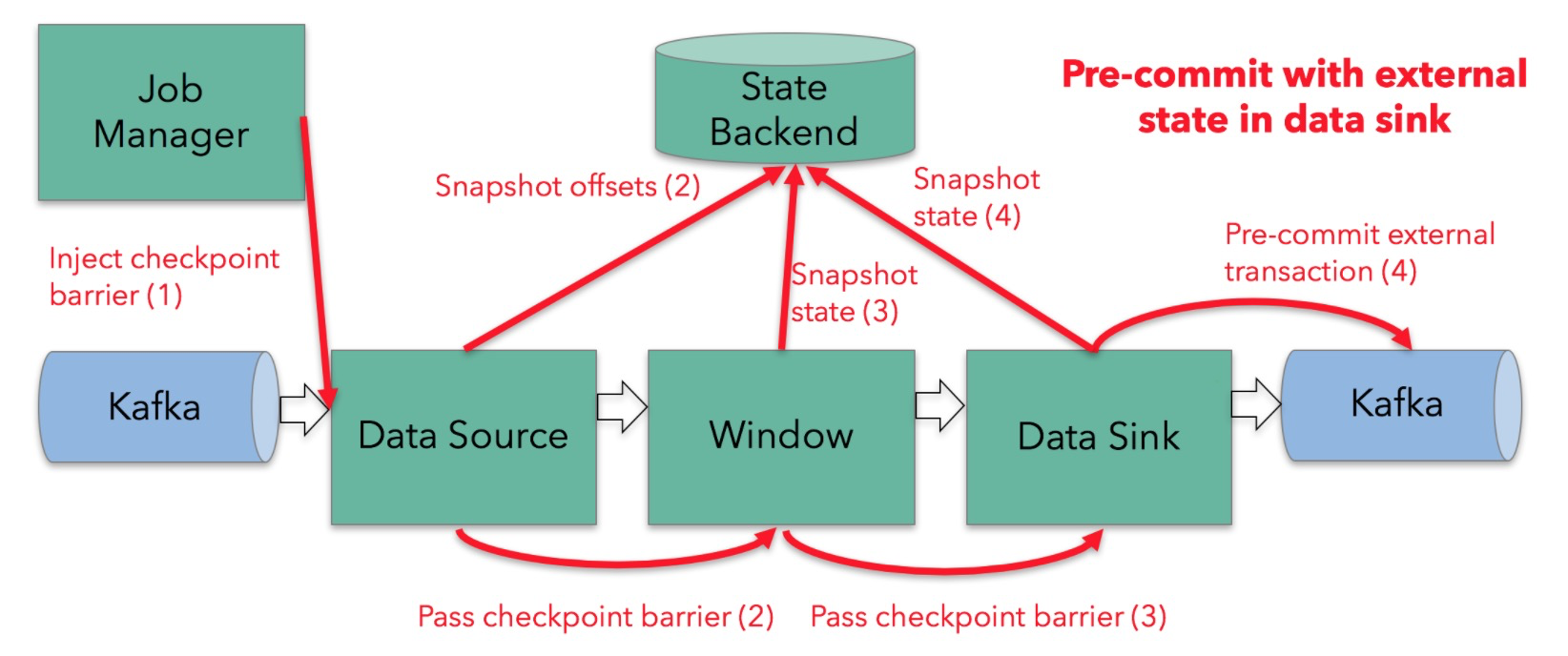
public void snapshotState(FunctionSnapshotContext context) throws Exception {
// this is like the pre-commit of a 2-phase-commit transaction
// we are ready to commit and remember the transaction
checkState(currentTransactionHolder != null, "bug: no transaction object when performing state snapshot");
long checkpointId = context.getCheckpointId();
LOG.debug("{} - checkpoint {} triggered, flushing transaction '{}'", name(), context.getCheckpointId(), currentTransactionHolder);
preCommit(currentTransactionHolder.handle);
pendingCommitTransactions.put(checkpointId, currentTransactionHolder);
LOG.debug("{} - stored pending transactions {}", name(), pendingCommitTransactions);
currentTransactionHolder = beginTransactionInternal();
LOG.debug("{} - started new transaction '{}'", name(), currentTransactionHolder);
state.clear();
state.add(new State<>(
this.currentTransactionHolder,
new ArrayList<>(pendingCommitTransactions.values()),
userContext));
}
@Override
public void initializeState(FunctionInitializationContext context) throws Exception {
state = context.getOperatorStateStore().getListState(stateDescriptor);
boolean recoveredUserContext = false;
if (context.isRestored()) {
LOG.info("{} - restoring state", name());
for (State<TXN, CONTEXT> operatorState : state.get()) {
userContext = operatorState.getContext();
List<TransactionHolder<TXN>> recoveredTransactions = operatorState.getPendingCommitTransactions();
for (TransactionHolder<TXN> recoveredTransaction : recoveredTransactions) {
// If this fails to succeed eventually, there is actually data loss
recoverAndCommitInternal(recoveredTransaction);
LOG.info("{} committed recovered transaction {}", name(), recoveredTransaction);
}
recoverAndAbort(operatorState.getPendingTransaction().handle);
LOG.info("{} aborted recovered transaction {}", name(), operatorState.getPendingTransaction());
if (userContext.isPresent()) {
finishRecoveringContext();
recoveredUserContext = true;
}
}
}
// if in restore we didn't get any userContext or we are initializing from scratch
if (!recoveredUserContext) {
LOG.info("{} - no state to restore", name());
userContext = initializeUserContext();
}
this.pendingCommitTransactions.clear();
currentTransactionHolder = beginTransactionInternal();
}
}